コンセンサスアルゴリズムというのをざっくり言うと、故障の発生し得るノードの集合が、整合性を持ったグループとして 1 つの値を決定する仕組みを指します。
このアルゴリズムの具体的な例として、Paxos と Raft が挙げられます。
一方で Consul
ちなみにですが、概要の概要だけ掴みたいっていう人は、以下のサイトで Step by Step で追っていくのも良いかなと思います。

Paxos との関係
Raft は Paxos の後に生まれたアルゴリズムです。Raft が生まれる前まで、コンセンサスアルゴリズムといえば Paxos、というのが世の中の流れでした。 一方で、Paxos の欠点としては、何よりその分かりづらさが挙げられています。
The first drawback is that Paxos is exceptionally difficult to understand.
(意訳) 最初の欠点は、Paxos を理解するのがめっちゃむずかしいってこと。
We struggled with Paxos ourselves; we were not able to understand the complete protocol until after reading several simplified explanations and designing our own alternative protocol, a process that took almost a year.
(意訳) ぼくたちも Paxos がんばってみたんだけど、単純化された説明をいくつか読んだり、代わりのプロトコルを考えたりしたんだけど、一年かかっても完全なプロトコルは理解できなかったよ。
分かりづらいが故にその実装も難しく、また、Paxos の問題を改善をしようとすればするほど、Paxos に与えられた「厳密な証明」が無価値になる、というのが大きな課題であったようです。 (このあたりは、Google が開発した Chubby の論文でも挙げられています)
このため、Raft の最大の設計目標は、「understandability」になっています。
Raft のアルゴリズム
Raft は、understandability を向上させるために、取り組むべき問題空間を以下の 3 つに分割しています。
- リーダー選出
- ログのレプリケーション
- ここでの「ログ」というのは、「x を 3 にしろ」とか、そういう命令を指しています。このログを、ステートマシンに食わせてクラスタ内のクライアント全体に配布します。
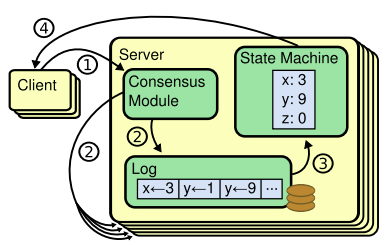
- ここでの「ログ」というのは、「x を 3 にしろ」とか、そういう命令を指しています。このログを、ステートマシンに食わせてクラスタ内のクライアント全体に配布します。
- アルゴリズムとしての安全性
リーダー選出
前提として、Raft には 以下の 3 つの状態がノードが取る状態として定義されています。
- leader
- candidate
- follower
基本的には leader が follower/candidate に対し、この「ログ」を適用するんやで、という指示を行います。その意味で、Raft においては、Leader に特権が与えられており、 この leader をどのようにして選出するか、そして、どのようにしてクラスタ内に 1 リーダーしか存在しない状態にするか、というところがミソになります。
最初に前提知識として、Raft では、論理的時間として、"Term" という概念が登場しています。 "Term" は任意の長さを持つ単位時間で、その中では最初に選挙が行われ、そこで選出された Leader は次の選挙が行われるまで(=その Term が終わるまで) Leader という扱いになります。
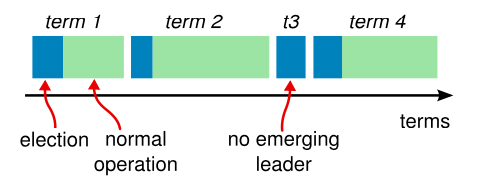
まず、Raft に参加するノード(サーバ)はすべて follower から始まります。
follower は、leader から Heartbeat (実体は AppendEntries という、ログレプリケート用の RPC) を受信する限り何もしません。なぜなら、すでにクラスタ内に leader がいることが明らかだからです。
一方、一定時間 Heartbeat が届かないと、follower は「おや、クラスタ内にリーダーがいないんじゃね?」と判断して、Candidate になり、「選挙(election) しようぜ」という RPC (RequestVote RPC) を周囲に撒き散らします。
これがリーダー選出の開始です。これを受けとったクラスタ内サーバは、最初に受信した Heartbeat 送信元の candidate に投票します。
Leader になるのは、クラスタ内のサーバの過半数から投票された Candidate です。この「過半数」の制限によって、クラスタ内に Leader が高々 1 つしかいない、ということが保証されます。
また、これが Raft の可用性に対する言及にもなっていまして、 個のサーバで構成されるクラスタにおいては、
個のサーバがいる限りにおいて Raft は正しく動作します。
Candidate が Leader になると Heartbeat を送信しますし、逆に Heartbeat を受信した Candidate は Follower に戻ります。

ログレプリケーション
ログレプリケーションっていうと、ログファイルに書くログエントリをレプリケートするの?って思ってしまいそうなんですが、ここでの「ログ」は前述の通り、ステートマシンに適用する命令列のことです。 ステートマシンは Raft に参加するサーバがそれぞれ持っているので、各サーバが同じ値を持つためには、同じログを各サーバにレプリケートする必要があります。
Leader は、ログ(命令列)をクライアントから受け取ると、AppendEntries RPC を撒き散らします。
この AppendEntries RPC は、他の Follower に対して「このログをお前らもローカルのステートマシンに適用するんやで」という要求になっています。
これを受信した Follower は、自分のステートマシンにログを適用して、リーダーと同じ情報を持つということになります。
ただ、重要なのは、あくまで情報のマスタは Leader が持っていることです。
Leader はこの状態ではまだ "commit" を行っていません。Leader が "commit" を行うのは、AppendEntries に対する正常応答を過半数の Follower から受け取ったときです。
Leader が "commit" してはじめて、マスタに反映する形になります。
クラスタ間でログに齟齬が発生したら???
では、ここでクラスタ間に情報に齟齬が発生したらどうなるか。
例えば、以下の例では Leader が log index 10 までの情報を持っている状態ですが、Follower である a は 9 までしか情報を持っておらず、(c) や (d) はもっと先の情報まで持っています。
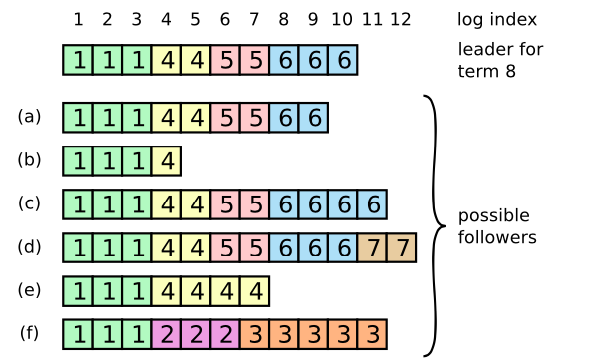
この齟齬を修正する責務は Leader にあります。 Leader は、齟齬がある Follower との間で以下のような処理を行います。具体的にこの処理をどのように実装するのかは論文を見てくれ。
- 互いのログにおいて共通祖先を見つける
- Follower のログのうち、共通祖先以後の情報(つまり、Leader が持っていない情報)を削除する
- Leader のログのうち、共通祖先以後の情報(つまり、Leader のみが持っている情報) を Follower のログに追記する
安全性
だいたいこれまでに書いた内容で大まかな Raft の動作としては正しくなるんですが、いくつかコーナーケースが存在してしまいます。 このため、実際の Raft では、もうすこし制約が課されることになります。
1. 十分に新しいログエントリを持っている Candidate にのみ投票する
ここで課される制約は、「Follower は、自分の持っているログエントリよりも新しいか同じログエントリを持っている Candidate にしか投票してはいけない」ということです。
例えば、古いログエントリしか持ってないサーバが Leader になった場合、他のサーバ(Follower)から、必要なログエントリを同期してもらわなければなりません。 これをしようとすると、Leader と Follower の関係が逆になり、プロトコルとしても複雑になってしまいます。
このような状況を防ぐために、十分にあたらしいログエントリを持ったサーバでないと Leader になれないようにしています。
2. 前の Term で未 Commit のログエントリはコミットしない
前の Term で未コミットのログエントリに対し、現 Term での Leader はコミットしないというのが制約です。
これ、説明するのが結構むずかしいコーナーケースなんですが、この制約がない場合、特定の状況において「一度 Commit したログエントリの上書き」が発生してしまうという問題が生じます。
クラスタのメンバーシップ変更
故障したマシンを取り替えるとかそういう場合、旧構成から新構成に移行していく必要があります。 もちろん、全ノードを停止させ、設定を変更し、全ノードを起動させるのが簡単ではありますが、再起動させるまでサービスを提供できないという状況は避けなければなりません。
こういった構成変更は Raft に取り込まれており、概要としては、旧構成 → 新旧が入り混じった構成 → 新構成というステップを踏んで移行するという方法になります。 Raft は 1 クラスタ内で高々 1 Leader しか存在しないことに強く依拠しているので、旧構成と新構成でそれぞれ Leader が選出されてしまうことや、それぞれで異なった合意が為されてしまうことは防がなければなりません。 このため、中間のフェーズである「新旧が入り混じった構成」においては、両構成における過半数の合意がなければならない、という仕様になっています。
このあたりは論文自体もすごくややこしくて、うーんよくわからんという部分も多いのですが、以下のエントリに興味深い内容が書かれていて、博士論文の側ではもっとシンプルな内容になっているようです。
http://akiradeveloper.hatenadiary.com/entry/2017/02/20/132326
Consul だとどう実装してんだ…?
ログエントリのコンパクション
論文読んでて、この仕組みだと、ログエントリ消せなくない???肥大化していかない????と思っていたら、そのあたりについても言及がありました。
単純な方法でいうと、Chubby や ZooKeeper が使っているスナップショットがあり、(厳密に同じではないにせよ) Raft も同じような仕組みを取っているようでした。 具体的には個々のサーバは、自分のローカルにあるログエントリとメタデータをストレージに保存して、ログエントリは消すという内容です。