そういえば昔、Java のアプリでログレベルを動的に変更したいんじゃ、という要望がありました。
当時、結局その要望は諸事情によって受けられなかったんだけど、Logback
logback.xmlを監視する- logback の提供する JMX を使用する
logback.xml の定期監視
logback には、logback.xml の修正結果を自動的にリロードしてくれる機能がある。デフォルトでは OFF なんだけど、設定ファイルの root 要素である configuration の scan 要素を明示的に true に指定することで有効化される。
<configuration scan="true"> ... </configuration>
この設定によって別スレッドが立ち上がり、定期監視が行われる。ソースを見る限り、「変更」の判断は ConfigurationWatchList の以下のメソッドで行われているようで、基本的には lastModified で変更検知される。
public boolean changeDetected() { int len = this.fileWatchList.size(); for(int i = 0; i < len; ++i) { long lastModified = (Long)this.lastModifiedList.get(i); File file = (File)this.fileWatchList.get(i); if (lastModified != file.lastModified()) { return true; } } return false; }
アプリケーションが起動しているときにログ設定を変えたいニーズというのは、以下のような場合だと思うけど、変更後の logback.xml で変更前の logback.xml を上書けば良いということになる。
- 監視不要だけどアラートが発行されちゃうログエントリを一時的に出力しないようにする
- 異常動作のトラブルシュートのために、特定のクラスのログを出力するようにする
監視間隔はデフォルトで 1 分。それが遅すぎる、というような場合は、さらにl scanPeriod 要素でその間隔を指定する。以下の例は「秒」単位指定だけど、最小粒度だとミリ秒単位で指定できる。
これほどの粒度でのファイル監視が、いったい何のニーズなのかはよくわからん。
<configuration scan="true" scanPeriod="30 seconds" > ... </configuration>
JMX を利用する
logback は、その設定を JMX 経由でも許可している。 実行方法は簡単だけど、Web アプリに載せるときには結構注意しないとメモリリークが発生する。
実行方法は、以下のように jmxConfigurator 要素を設定ファイルに追加するだけ。
<configuration> <jmxConfigurator /> ... </configuration>
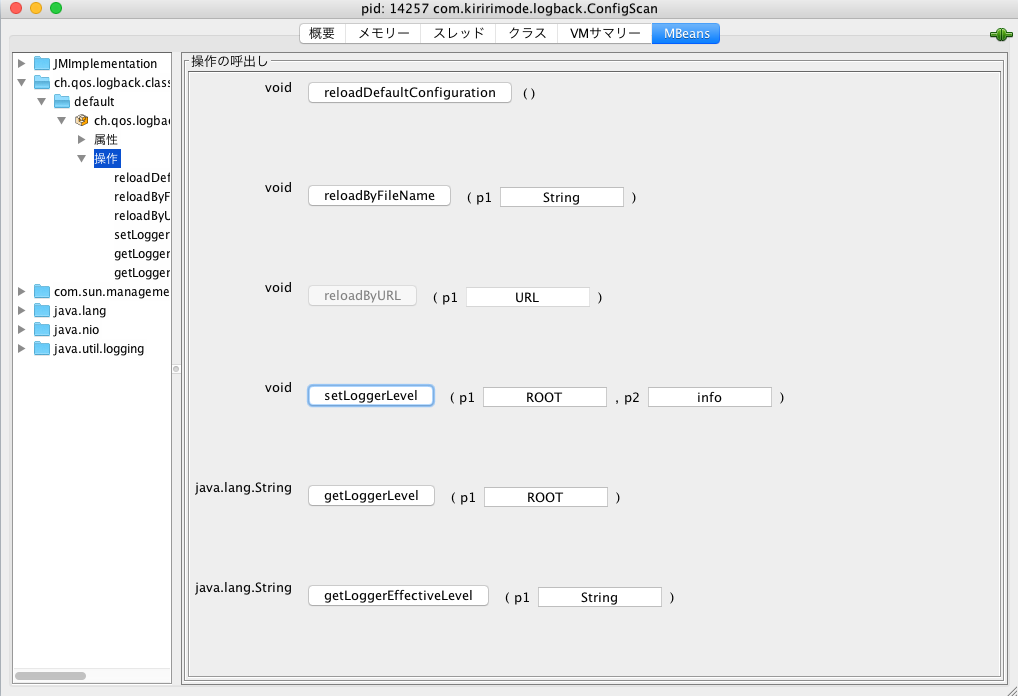
これにより、jconsole でアプリケーションに接続すると、以下のような UI が立ち上がる。
ここでは ROOT ロガーのログレベルを INFO に変更したけど、その変更は確かにアプリケーション側に反映された。
WEB アプリに載せるときの注意というのは、WEB/APP サーバから JMXConfigurator への参照が解除されず GC されないことに明示的に対応が必要なことで、このあたりの問題は Logback だけでなく
Log4j2 とかにもあるようだった。Logback については、ServletContextListener#contextDestroyed あたりで、
import javax.servlet.ServletContextEvent; import javax.servlet.ServletContextListener; import org.slf4j.LoggerFactory; import ch.qos.logback.classic.LoggerContext; public class MyContextListener implements ServletContextListener { public void contextDestroyed(ServletContextEvent sce) { LoggerContext lc = (LoggerContext) LoggerFactory.getILoggerFactory(); lc.stop(); } public void contextInitialized(ServletContextEvent sce) { } }
とかすれば良い模様。







![JavaデベロッパーのためのEclipse完全攻略[4.x対応版]](https://m.media-amazon.com/images/I/616I3atMQKL._SL500_.jpg "JavaデベロッパーのためのEclipse完全攻略[4.x対応版]")




_Prevention_Cheat_Sheet)

")



