会社の中でシェルスクリプトについての話をすることにしたので、このエントリはそのためのものです。 個人的な好みとかもいろいろ入ってしまっているので、そのあたりは取捨選択してください。
なぜ今シェルスクリプトを学ぶのか
シェルスクリプトはあまり日の目を見ることがなくなってきました。 ではシェルスクリプトの知識が不要かというとそんなことはなく、むしろその重要性は高まっていると感じています。
まずシェルスクリプトとはどのようなものでしょうか。
実行するべきコマンドをあらかじめファイルに書いておき、そのファイルをシェルに読み込ませて実行することができます。これはシェルスクリプトです。
もちろん単にコマンドを羅列するだけでなくif文やwhile文等も使えますが、シェル自身はほとんど処理を行えず、ほとんどの作業は他のプログラムを呼び出すことによって実現されます。 これは欠陥のようにも見えますが、むしろこれが長所だと考えています。
結果として、詳解シェルスクリプトに記載のある以下の状況が、さらに進んでいると理解しています。
ある1つの機能に特化したツールを多数作成し、これらを自由に組み合わせて目標とする処理を行う」というUnixの思想がより確固としたものになりました。 その結果として、シェルスクリプトから利用できるツールがますます増えてゆくという好循環が発生することになりました。
いくつか、この例をあげます。
公開されているSRE本をマルっとPDF化する
# SRE本ページの目次コンテンツを取得 curl -s https://landing.google.com/sre/book/index.html \ # CSSセレクタで目次からリンクされている「本文」のページURL一覧を取得 | pup 'div.content a[href] attr{href}' \ # HTMLをPDF化するツール「wkhtmltopdf」で綺麗に表示できるように、当該ツール用オプションを作成 | sed 's/\(\([^/]*\).html\)$/\1 \2.pdf/' \ | sed 's|^|--disable-smart-shrinking --viewport-size 800x600 --zoom 3 --resolve-relative-links https://landing.google.com|' \ # オプションをパイプ経由でwkhtmltopdfに読み込ませ、HTMLをPDF化する | wkhtmltopdf --read-args-from-stdin # ページ数分PDFファイルが作成されるので、一つに結合する /System/Library/Automator/Combine\ PDF\ Pages.action/Contents/Resources/join.py --output sre.pdf $(ls -tr *.pdf)

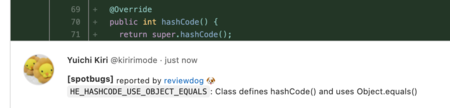
SpotBugsのViolationレポートをMerge Requestのコメント投稿する
script: - mvn ${MAVEN_CLI_OPTS} compile spotbugs:spotbugs # SpotBugsのViolationをMerge Requestのディスカッションにコメントする - >- # SARIF形式のSpotBugsレポート(JSON)の内容をパイプへ送り込む cat target/spotbugsSarif.json # 違反したルールや違反したソース箇所の情報を jq で抽出し CSV 化 | jq -r '.runs[].results[] | [ "`" + .ruleId + "`: " + "*" + .level + "* " + .message.text, "src/main/java/" + .locations[].physicalLocation.artifactLocation.uri, .locations[].physicalLocation.region.startLine ] | @csv' # ReviewDogを使ってGitLabのMerge Requestにコメントする | bin/reviewdog -reporter=gitlab-mr-discussion -efm '"%m","%f",%l' -name="spotbugs" -tee
ぼくの互換性についての考え方
このエントリにも表れているのですが、ぼくのシェルスクリプトの互換性についての考え方は「他のOSにシェルスクリプトを持って行った時に動かなくても良い」です。
wikipedia:POSIX等のさまざまな標準は存在しますが、そもそもシェルスクリプトが「他のコマンド/ツール」を呼び出すことに特化している以上、互換性を保つためには それらコマンド/ツールにも互換性を求めざるを得ません。
そして、これらツールにおいてはOS間で互換性が保たれないどころか、コマンドの有無レベルの違いが常です。 このため、僕自身はシェルスクリプトに互換性を求めるくらいなら環境ごとに書き直して動作確認した方が早い、と考えています。
何で書くか
世の中にはさまざまなシェルがあり、それぞれのシェルの機能によってシェルスクリプトの形も異なります。
シェルの種類は大きくBシェル系、Cシェル系、Aシェル系の3種類に大別されます。
多くの場合はBシェル系とAシェル系の2種類と解説されるところですが、Ubuntuは/bin/shがdashにリンク1されるため、あえて3種類としてみました。
| 種類 | |
|---|---|
| Bシェル系 | sh、bash、ksh、zsh |
| Cシェル系 | csh、tsh |
| Aシェル系 | ash、dash |
では僕たちは何で書くのが良いのかというと、Bashで書くのが良いと考えています。 これはほとんどのシェルスクリプトがBashで記述されており、ノウハウがネット上に多数転がっていることが理由なのですが、定量的なデータを持ち合わせていません。 こういった時は天下のGoogle様がBashを使えと行っているからだ、と押し通しても良いでしょう。
シェルスクリプトをうまく書くには
ShellCheckを使う
シェルスクリプトのノウハウにはいろいろありますが、まず言えることはlintをかけること。 シェルスクリプトのlinterとしては、ShellCheck一強だと理解しています。
VS Code派の人はShellCheckを入れれば、まずいところが一覧されます。
バッドパターンとその修正
ここでは、ぼくが経験したバッドパターンをいくつかご紹介します。 あらかじめ断っておくと、これらバッドパターンが完全悪だとは思いません。 一方で、もう少しバグりにくい書き方があることを知っておくのは選択の幅が広がります。
line-by-lineの処理が多い
line-by-lineの処理が多いことは、特段悪いことではありません。 以下のようなシェルスクリプトは、身近なところでもよく見ます。
while read line; do hoge=$(echo "$line" | cut -c1-15) fuga=$(echo "$hoge" | awk 'hogefuga') # 以降、かなり長い done <input_file
これが問題になり始めるのはinput_fileの中身が数万行になるといった場合です。
こうなると、ループの中のコマンドの起動負荷(=forkの負荷)が目立ち始めます。
ぼくの経験したのはシェルスクリプトのバッチ機能が10時間経っても終わりませんというエスカレーションで、
その原因がこのような実装でした。
シェルスクリプトは他のコマンドを呼び出す時にプロセスを起動する(=forkする)こと、
そして、forkの負荷は高いということを理解しておかないと「仕方がない」とされてしまいます。
このパターンについては、もし記述できるのであればパイプを使った処理に置き換えることで解消が図れます。 ぼくが経験した時は、そのように対応することで10時間の処理が10分程度まで短縮できました。
パイプ化が難しければ、もう少し早い言語で書き直したが良いのではないでしょうか。
lsを使う
lsの出力はかなり変動しやすく解析もしづらいです。
ls /directory | grep mystring
シェルスクリプトでlsを使うケースは、多くの場合グロブで書き直せるでしょう。
$ ls /directory/*mystring*
ls | grep -v 'log$'
ディレクトリ中に含まれるファイルを全て取得したいが、特定の文字列を含むファイルを除外したい。 このケースでは拡張Globと呼ばれる機能を利用します。
# 全ファイルを表示 $ ls -1 kiririmode.fuga kiririmode.hoge kiririmode.log # grepで`.log`で終わるファイルを除外 $ ls -1 | grep -v '.log$' kiririmode.fuga kiririmode.hoge # 拡張Globで`.log`で終わるファイルを除外 $ shopt -s extglob $ ls -1 !(*.log) kiririmode.fuga kiririmode.hoge
拡張Globについては、以下のエントリで簡単にまとめています。
lsの結果をループさせる
以下のようなループが典型例です。
for l in $(ls *); do echo "$l" done
ディレクトリ内のファイル名を出力するだけの処理ですが、例えばスペースを含むファイル名でバグります。
$ touch 'this file includes spaces' $ ls 'this file includes spaces' $ for f in $(ls *); do echo file name is "\"${f}\"" done file name is "this" file name is "file" file name is "includes" file name is "spaces"
これもGlobを使うべきところです。
$ for l in *; do echo file name is "\"${l}\"" done file name is "this file includes spaces"
良いシェルスクリプトを書くためのTIPS
set -euする
スクリプトの中でset -euしておくと、以下の効果が得られます。
-e: スクリプト内のコマンドがエラー終了した場合、スクリプトを自動的に終了する-u: 未定義変数を使おうとするとエラー終了する
-eについては使い所に依るところです。場合によってエラー終了するコマンドに対し、そのエラー処理もスクリプトに記述するケースはあるからです。
文字列は基本的にクオートする
とりあえず脳死して、文字列を含む変数はダブルクオートで囲む。できれば{}でも囲む。
これだけで、ずいぶんシェルによる(意図せぬ)分割に起因したミスが減ります。
$ var="hoge" $ echo $var hoge $ echo "${var}" # better hoge
局所変数にはlocalを使う
関数専用の変数はとにかくローカル変数にしましょう。他の言語と同じです。
func1() { local var="hoge" echo "${var}" } var="fuga" func1 # prints "hoge" echo "${var}" # prints "fuga"
定数は読み取り専用にする
他の多くの言語と同じように、変数は宣言タイミングで読み取り専用(定数)にできます。
$ readonly NAME="kiririmode" $ NAME="pondering" bash: NAME: readonly variable
また、他の多くの言語とは異なり、変数を後段で読み取り専用にできます。
$ RONLY_LATER="fuga" $ RONLY_LATER="hoge" $ readonly RONLY_LATER $ RONLY_LATER="piyo" bash: RONLY_LATER: readonly variable
条件はif [...]ではなくif [[...]]を使う
[はかなり低機能である一方、[[は[が持ち込む落とし穴を回避できるように高機能になっています。
以下、同種の意味を持つ書き方を並べてみましたが、全然書き味の違うことがわかるのではないでしょうか。
$ [ -f "$file1" -a \( -d "$dir1" -o -d "$dir2" \) ] # グルーピング用の括弧もエスケープの必要有 $ [[ -f $file1 && ( -d $dir1 || -d $dir2 ) ]]
$ [ -f "$file1" -a \( -d "$dir1" -o -d "$dir2" \) ] # グルーピング用の括弧もエスケープの必要有 $ [[ -f $file1 && ( -d $dir1 || -d $dir2 ) ]]
このあたりは以下のエントリにまとめていました。
コマンド置換はback-tickではなく$()を使う
可読性が高いこと、コマンド置換を入れ子にできるのがメリットです。
$ echo $(dirname $(which ls)) /usr/local/opt/coreutils/libexec/gnubin
算術演算は(( ))を使う
シェルスクリプトで算術演算する方法としてはさまざまありますが、整数演算なら(( ))を利用するのが一番楽です。
$ sum=$((1+2+3+4+5+6+7+8+9+10)) $ echo $sum 55 $ echo $((11/5)) 2 $ echo $((11%5)) 1
条件分岐時にも利用できます。
for i in {1..10}; do
((i > 7)) && echo "${i}"
done
8
9
10
使える演算子は多く、インクリメントや累乗、シフト演算等も使えます。
$ i=5 $ echo $((i++)) # インクリメント 5 $ echo $((2**i)) # 累乗 64 $ echo $((2**i << 2)) # シフト演算 256
実数の演算にもさまざまな方法はありますが、bcを覚えられないので、ぼくはawkを使っちゃうことが多いです。
$ div=$(awk 'BEGIN{ printf("%4.2f\n", 11.0/5) }') $ 2.20
パイプでエラーが起こった場合のためにpipefailを有効化する
コマンドをパイプで繋げたとき、前段のコマンドが失敗してもコマンド全体としての終了ステータスが0(=成功)になるケースがある。
$ hoge | ls -a bash: hoge: command not found . .. $ echo $? 0
これを防ぐためには、pipefailを有効化します。
pipefailは、パイプ全体の終了ステータスを、パイプで繋がれたコマンドのうちで非0を返したコマンドの終了ステータスにします。
$ set -o pipefail $ hoge | ls -a bash: hoge: command not found . .. $ echo $? 127
パイプで繋がれるコマンドそれぞれの終了ステータスはPIPESTATUSを参照する
パイプで繋がれるエラー処理を行う場合、パイプで繋がれる終了ステータスはPIPESTATUS変数の値で取得できます。
$ exit 3 | exit 4 | exit 5 $ echo ${PIPESTATUS[@]} 3 4 5
サブシェルによる安全な設定変更
(command1; command2)というように、()で囲まれた箇所はサブシェルにより実行されます。
これを使うと、シェル変数の変更やカレントディレクトリの変更といった影響を、サブシェル内のみに収めることができます。
使い所としては、一時的なシェルオプションの変更(例: shopt -o extglob)等ですね。
$ var="hoge" $ pwd /Users/kiririmode/work $ (cd childdir; pwd; var="fuga"; echo "${var}") # サブシェルの中でコマンド実行 /Users/kiririmode/work/childdir fuga $ pwd; echo "${var}" # サブシェルの外でコマンド実行すると、サブシェルの変更は当然反映されない /Users/kiririmode/work hoge
グループコマンドを使ったリダイレクトの簡素化
以下のように、毎回同じファイルへ書き込むために都度リダイレクトを行うケースがあります。
echo "This message goes to " >> hoge echo "hoge file" >> hoge
実は{}で囲ったコマンド群は同一シェル内であたかも1つのコマンドのように実行できます。
これを利用すると、上記のようなリダイレクトを簡素化できます。
$ { echo "This message goes to" echo "hoge file" } >hoge $ cat hoge This message goes to hoge file
終了処理にはtrapを使う
シグナルハンドラを設定できるtrapですが、擬似シグナルEXITを使うと、スクリプト終了時の処理を指定できます。
function cleanup() { rm -f ./cleanup-target echo "cleaned up!" } trap cleanup EXIT
パラメータ展開を積極的に利用する
echo "${var}" | cutやecho "${var} | sed等で文字列処理を行うケースを良く見ますが、シェルのパラメータ展開はかなり優秀です。
| 記法 | 解説 |
|---|---|
${var:-default} |
varが未設定あるいは空文字列の場合に、defaultに展開される |
${var-default} |
varが未設定の場合に、defaultに展開される |
${var:=default} |
varが未設定あるいは空文字列の場合に、defaultがvarに代入される |
${var=default} |
varが未設定の場合に、defaultがvarに代入される |
${var:?error} |
varが未設定あるいは空文字列の場合に、errorを出力してシェルスクリプトを終了する |
${var?error} |
varが未設定の場合に、errorを出力してシェルスクリプトを終了する |
${var:+value} |
varが空文字列以外に設定済の場合にvalueの値に展開される |
${var:+value} |
varが設定済の場合にvalueの値に展開される |
${#var} |
varの文字列長に展開される |
${var#pattern} |
varの文字列の左側からpatternに一致する最短の部分が取り除かれる |
${var##pattern} |
varの文字列の左側からpatternに一致する最長の部分が取り除かれる |
${var%pattern} |
varの文字列の右側からpatternに一致する最短の部分が取り除かれる |
${var%%pattern} |
varの文字列の右側からpatternに一致する最長の部分が取り除かれる |
${var:offset} |
varの文字列の左側からoffset個の文字列が取り除かれた値に展開される |
${var:offset:length} |
varの文字列の左側からoffset個の文字列が取り除かれた長さlengthの値に展開される |
${var/pattern1/pattern2} |
varの文字列の左側から最初に一致したpattern1の部分がpattern2に置換される |
${var//pattern1/pattern2} |
varの文字列の左側からpattern1に一致した全ても部分がpattern2に置換される |
わかりづらそうな利用用途をサンプルとともに記載してみます。
# パラメータ設定時のみの展開 $ LD_LIBRARY_PATH=/usr/local/myapp/lib${LD_LIBRARY_PATH:+:}$LD_LIBRARY_PATH # 先頭文字列の除去 $ echo "${HOME}" "${HOME##*/}" # basename 相当 /Users/kiririmode kiririmode $ echo "${file}" "${file#*.}" "${file##*.}" # 拡張子の取り出し hoge.tar.gz tar.gz gz # 文字列長 $ echo "${msg}" "${#msg}" hello world 11 # 部分文字列 $ echo "${msg:6}" world
情報源
書籍
Web上のリソース
ちなみにBashFAQはいろいろなテクニックが紹介されていて、めちゃくちゃ面白いです。
-
BashとDashの差異についてはbash vs. dashに概説があります。↩