生成AIを使った生産性向上というのは猫も杓子も取り組む領域なわけですが、特に「生成AIにコードを書かせる」場面では、AIが学習していないライブラリやフレームワークを使うときに大きな壁が立ちはだかる。AIは学習データに含まれていない情報には弱くて、正確なコードや使い方を提案できないことが多い。
この壁があるからこそ、ゼロショット(AIが事前学習だけで即座に使い方を提案できる)で使えるライブラリやフレームワークに集約していくのが理想的な方向だよなぁ、と思う。AIが即座に正しいコードを生成できる環境が整えば、開発効率が上がるわけで。いちいちコンテキスト渡してられるか、という思いもある。
でも、現実はそう簡単じゃない。ライブラリやフレームワークの良さの一つは、使っている限りは中身の品質が保証されていて、ブラックボックスとして安心して使えるところにある。これまで「生成AIがあまり学習していない」独自ライブラリやフレームワークで品質保証してきた組織は、そう簡単に他のライブラリやフレームワークに移行できない。移行にはコストもリスクもある。
仮に移行できたとしても、ゼロショットで使えるライブラリやフレームワーク自体も日々進化していく。AIの学習カットオフ時点以降の新機能や変更点はAIにとって未学習なので、これもまた大きな壁になる。AIは最新の使い方やAPIを知らないから、誤った提案をしてくることもあるわけで。
結局のところ、なんらかの形で生成AIに、これらライブラリやフレームワークの未学習部分をコンテキストとして注入してあげる必要がある。AIが正確な提案をするには、最新情報をその都度渡してあげないといけない。
その一つの方法が、先日エントリにしたGitHub CopilotのgithubRepo機能を使うこと。他の方法として、Context7 MCPサーバを利用するという選択肢もある。
Context7 MCPサーバとは
Context7 MCPサーバは、LLMやAIコードエディタ向けに「最新・バージョン別のコードドキュメントやサンプル」を返してくれるMCPサーバ。従来のLLMが抱えていた「古い情報・幻のAPI・汎用的な回答」といった問題を解決するために、実際のライブラリやフレームワークの最新ドキュメント・コード例を取得して、プロンプトに直接挿入できる。
Context7 MCP pulls up-to-date, version-specific documentation and code examples straight from the source — and places them directly into your prompt.
こういうアプローチをとっているMCPサーバとしては、Terraform MCP ServerやAWS Documentation MCP Serverなんかもある。
- Terraform MCP server overview | Terraform | HashiCorp Developer
- AWS Documentation MCP Server - AWS MCP Servers
Context7 MCPサーバの使い方
Remote Serverとして利用できるので、VS Codeならこんな感じで設定しておけばOK。ローカルで動かす必要がないのは、やっぱり楽でいい。
"mcp": { "servers": { "context7": { "type": "http", "url": "https://mcp.context7.com/mcp" } } }
Context7 MCPサーバで取得できる情報
じゃあ、Context7 MCPサーバはどこから情報を拾ってくるのか?というと、実態としてはcontext7.comのサイト上でインターネット上のライブラリやフレームワークのドキュメントを収集・パースして蓄えているっぽい。
収集対象は主に3つ。
- GitHub リポジトリ
- llms.txt
- Webサイト
GitHubリポジトリからの収集がメインっぽい。引っ張ってくるのは、.md、mdx、.html、.rst、.ipynb、adoc。全部の情報を蓄えているわけじゃなくて、コードサンプルを中心としたチャンクが対象。コードだけのリポジトリだとエラーになる。
実際、ライブラリの細かなAPIドキュメントを生成AIに渡すよりも、コードサンプルをFew-Shotとして渡した方が意味あるよね、という考え方なんだろうなと。
というわけで、試しにNablarchのドキュメントの収集もお願いしてみました。独自色が強くて、AIが学習していない部分も多いはず。
GitHubリポジトリから収集する場合、Github Releasesを使っていればバージョンを認識してくれるっぽいんだけど、NablarchはGitHub Releasesを使っていないので、Latestしか見えない。Releases使った方がいいなぁと思った。
上記URLを開くと分かるように、コードスニペットを中心に、ある程度の規模のチャンクがテキストとして蓄積されている。検索もできるので、なかなか便利。
GitHub Copilotから使ってみた体験
VS CodeでMCP設定をした上でGitHub Copilot agent modeから使ってみた。Nablarch BatchのDBアクセスをどうするかを聞いてみた結果がこちら。
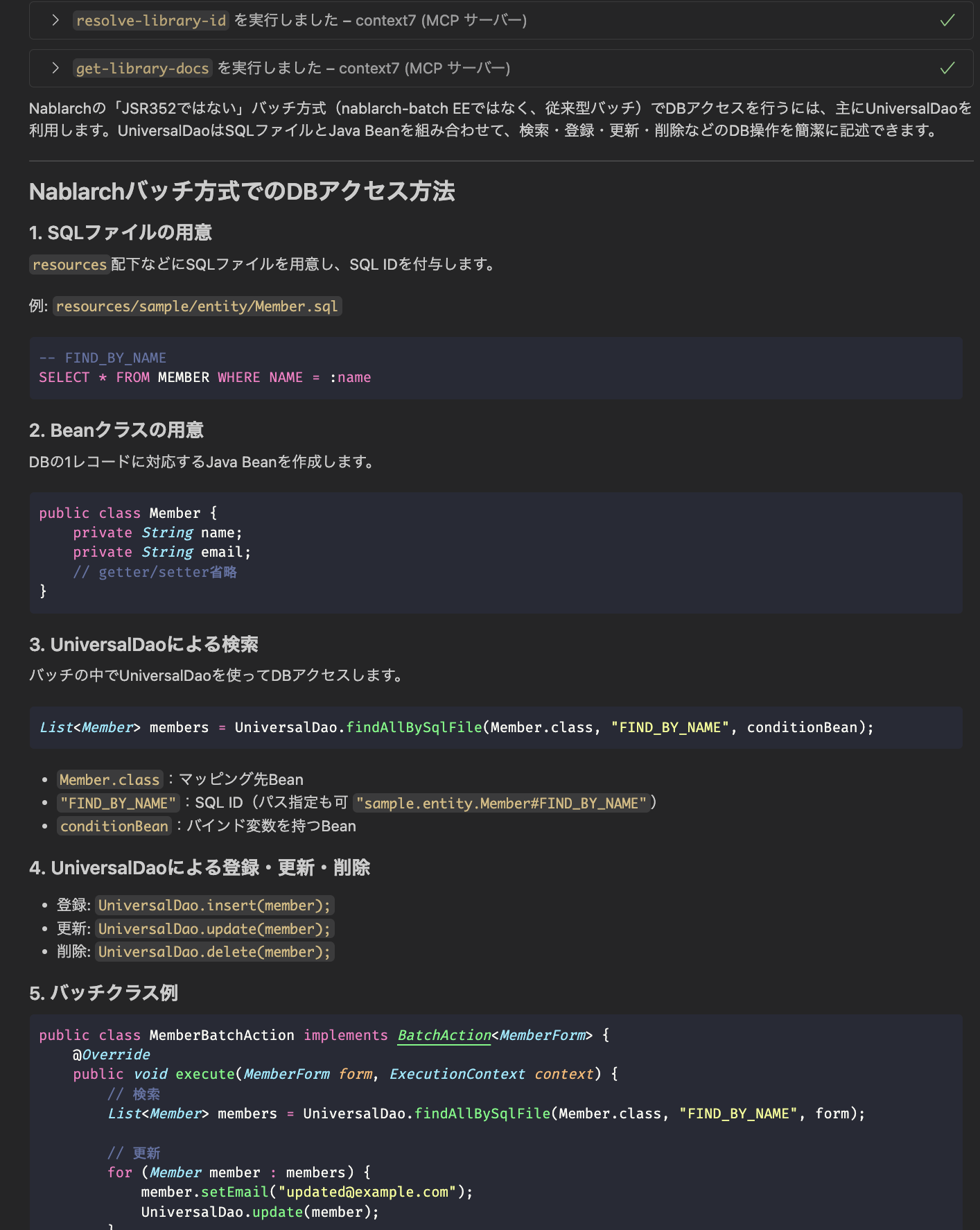
それっぽい回答してくれてる。何も情報がない状態で戦うよりは遥かにマシな感じ。
こちらはNablarchでREST APIを作った時、「レスポンスってどうやってJUnitでassertするんだっけ?」という問い合わせ。
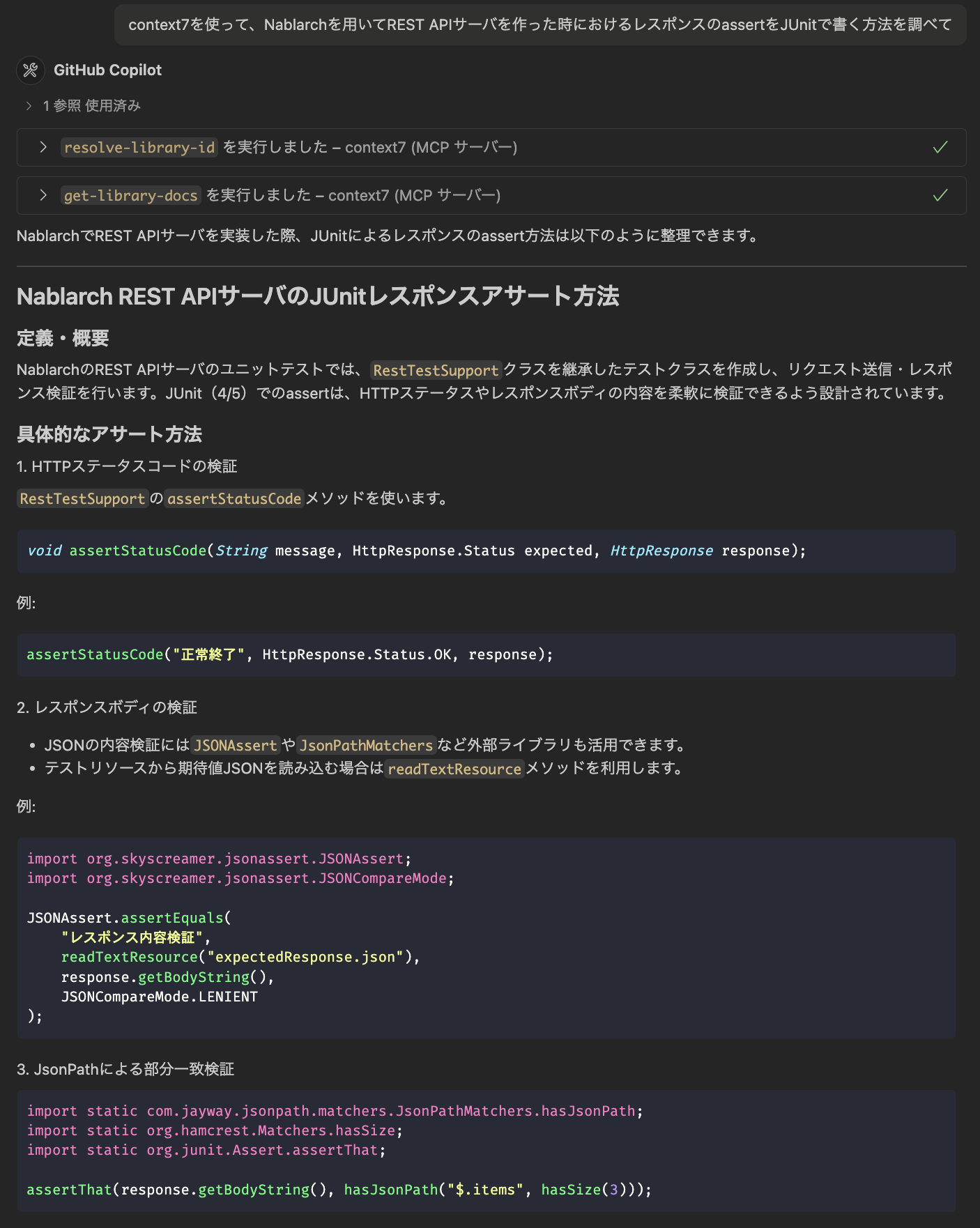
RestTestSupportっていうクラス、正直記憶になかったんだけど、実際に存在してました。readTextResourceメソッドのような細かいところも理解してくれていて、こういう情報がコンテキストにあれば精度の高いテストも書けそう。
ライブラリ・フレームワークのガイドと作者に求められるもの
Context7を使うかどうかはさておき、ライブラリやフレームワークが今後もっと生成AIネイティブに進化していくためには、そのAPIをどういう時にどう使ってほしいのかを、コードサンプルと一緒に示すガイドがやっぱり必要だなぁと改めて思った。ユーザ目線で書かれた、しっかりしたガイドが大事。それすらも生成AIで書く時代だけど、その前提としてライブラリ・フレームワークの作者は「ユーザにそのAPIをどう使ってほしいのか」という哲学をちゃんと持っておく必要があるなぁ、と強く思った。